PmPNet Structure
We implemented PmPNet as a convolutional residual autoencoder (RAE) with an additional prediction module. In our construction, the input of the PmPNet is a one-dimensional vector of length 297. It combines three parts: envelope, dist, evdp. The length 281 envelope is the normalized envelope of the vertical component of seismic signals, which has been resampled at 40 Hz and covers the time window from 2 s before to 5 s after the observed P-wave arrival. Dist refers to the epicentral distance, and evdp refers to the focal depth, both being repeated 8 times and concatenated to the end of the signal. The number of duplication 8 is chosen according to our experiments, and the final results presented in this paper are not sensitive to this selection.
PmPNet outputs three quantities: (i) the recovered input, (ii) the PmP travel time t (a positive real number), and (iii) the PmP probability p, a real number in [0, 1] representing the probability that the input seismic signal contains a PmP phase. PmPNet includes three major substructures: an encoder, a decoder, and a predictor. Similar to a standard AE, the encoder and the decoder are trained to regenerate the input. We train the predictor to read the latent variable (generated by the encoder) to predict the PmP probability p and travel time t. To be more precise, let x̃ be the output of the decoder, i.e., the recovered input. Then z = Encoder(x), x̃ = Decoder(z), and (p, t) = Predictor(z).
The main architecture of the PmPNet and the data flow inside the network: The input of the PmPNet is a one-dimensional vector combining three parts: signal envelope, epicentral distance, and focal depth; PmPNet outputs three quantities: the recovered signal (including signal envelope, epicentral distance, and focal depth), the PmP probability p and the PmP travel time t; PmPNet includes three major substructures: an encoder, a decoder, and a predictor.
Loss Function of PmPNet
Given a training input set \(\{x_{i}\}^{N}_{i=1}\) with N data points, the corresponding PmP label \(\{p_{true,i}\}^{N}_{i=1}\) and PmP travel time \(\{t_{true,i}\}_{i=1}^{N}\), we can optimize a PmPNet with trainable parameters set θ. Three different loss functions (\(l_{1}\), \(l_{2}\), \(l_{3}\)) are utilized for encoder-decoder, classification and travel time training respectively. The total training loss of PmPNet is the sum of three individual losses:
The variables involved are summarized as follows:
\(x_{i}\) is the input datum and \(x̃_{i}(θ,x_{i}) := Decoder_{θ}(Encoder_{θ}(x_{i}))\) is the recovered datum by the encoder-decoder pair.
\(p_{true,i}\) is the true PmP label picked by experts, which is either 0 or 1. Here \(p_{true,i}=1\) means that \(x_{i}\) has a PmP phase, while \(p_{true,i}=0\) means that \(x_{i}\) does not have a PmP phase.
\(t_{true,i}\) is the true PmP travel time, which is either manually picked for those labeled with PmP or theoretically computed by using the HK model (Hadley & Kanamori, 1977) for those labeled with non-PmP.
\((p_{i},t_{i}):=Predictor_{θ}(Encoder_{θ}(x_{i}))\) with \(p_{i}(θ,x_{i})\) and \(t_{i}(θ,x_{i})\) being the PmP probability and the PmP travel time, respectively.
Besides, each loss function is defined as:
\(l_{1}(x,x̃):=||x − x̃||_{1}\) is the L1 loss between input datum and recovered datum.
\(l_{2}(p,p_{true}):=-ωp_{true}log(p(x))-(1-p_{true})log(1-p(x))\) is the weighted cross-entropy loss with the weight ω chosen to be 20 balancing the importance of precision and recall.
\(l_{3}(t,t_{true}):=||t − t_{true}||_{1}\) is absolute difference between the true traveltime and predicted traveltime.
Performance of PmPNet
The validation performances of PmPNet shows that The proposed PmPNet can reach high precision(96.6%) and recall(85.3%) simultaneously. The average travel time absolute difference is around 0.33s, while maximum difference constantly stays within 5s.
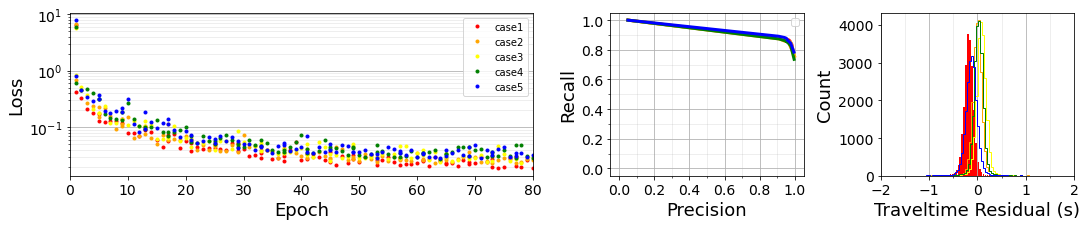
The total training loss decreases as the epoch increases. The precision-recall curve on validation set. The PmP traveltime residual between the predicted and manually picked ones on validation set.
The recovered input can capture most of the patterns from the input signal, which indicates the latent variable is indeed a good representation of the input.
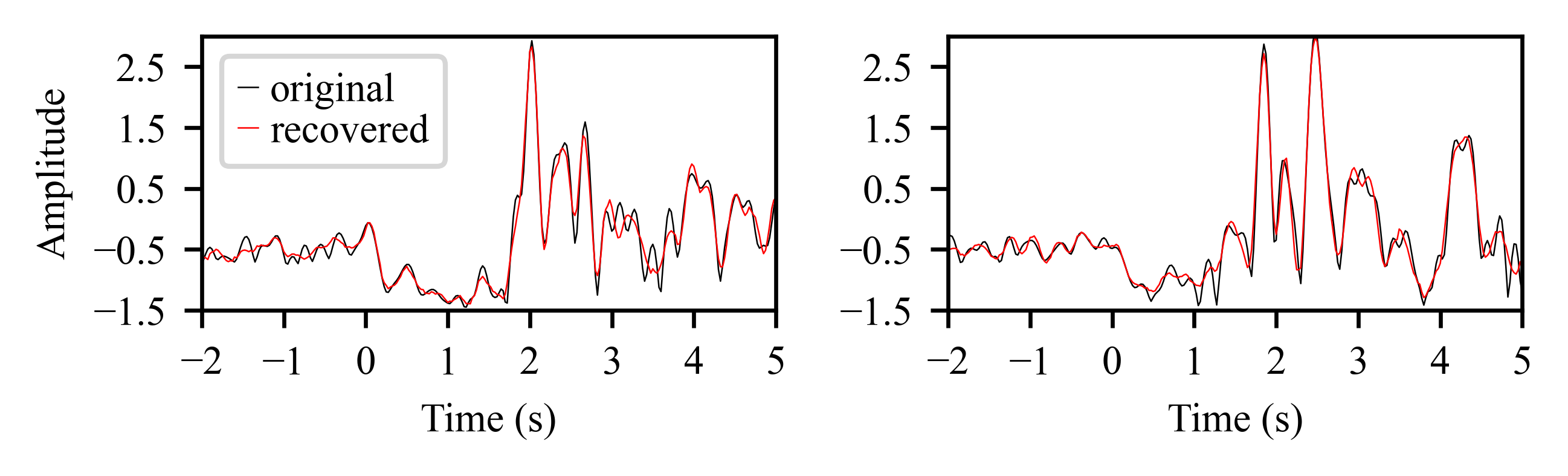
The PmPNet recovered input and the input component on validation set.
Applying the trained PmPNet to the 19-year long vertical-component seismic data from January 2000 to December 2018, we are going to automatically identify the waveforms which could contain high-quality PmP waves. To achieve the goal, we select the waveforms with the PmP label with a probability of larger than 0.8. Result shows that the trained PmPNet has successfully recalled the most PmP waves (larger than 96 %) before 2011, and even for the seismic data after 2010 which are not involved in training the PmPNet, there is also a high recall value of larger than 85 %.

PmP picks when applying the trained PmPNet to real data. Blue bars show the picked PmP waves each year by the two-stage workflow, orange bars show the identified PmP waves each year by the PmPNet with the probability of greater than 0.8, and green bars show the overlapped PmP waves each year between the two identifiers.